Innovation to Impact. See you at the July ESIP Meeting.
Guest Blog: Building Trust in Machine Learning Outputs
In his guest blog, 2022 Community Fellow Michael Mahoney shares some of the challenges of applying machine learning to remote sensing data as well as a recent success: a new paper from his lab at SUNY College of Environmental Science and Forestry.
Seeing the forest for the trees is akin to seeing the map for the data. Credit: Olga Sergienko via Unsplash
A lot of my work focuses on mapping things that are hard to measure — things like forest biomass and how it changes from year to year and young, regenerating forestlands, which only exist for a few years before they mature into different, distinct ecosystem types.
If you had infinite time and money, you could feasibly go out and measure these traits across every inch of the landscape and get a high-quality, high-resolution, and highly-accurate map. Because my lab has neither, we've turned to using remote sensing and machine learning to model forests in areas we haven't measured. And we've had some success, too — our high-resolution forest biomass maps for New York, built as part of New York's project to hit net zero emissions under the Climate Leadership and Community Protection Act, are among the most accurate in the literature.
But as the old joke goes: everyone trusts the data except the person who collected it; no one trusts the model except the person who made it.
Machine learning approaches have garnered quite a bad rap in applied fields in recent years. Not least because of a number of poorly validated global models based on data collected across sub-global extents, which fail to accurately report uncertainty, or for that matter to accurately reflect conditions on the ground. How can we start to build trust in our models that will be needed if our maps are going to inform land management and climate action?
I don't have the entire answer, but I can share how we've started to approach the problem.
More than pretty pictures
Our lab makes a point of being extremely thorough with our accuracy assessments, presenting multiple metrics of accuracy both at the individual map pixel scale and at multiple aggregation levels, to give a sense of how model errors compound (or don't!) when considering larger areas. As put by researchers at the US Forest Service, we want to make sure we’re producing more than just a pretty picture.
We also make a point of only reporting the accuracy that matters, calculated against ground-truth data held out in a test set not used for building models. Reporting additional accuracy metrics calculated against training set observations or the outputs of another model will probably give an overoptimistic and confusing picture of how well the map performs in the real world.
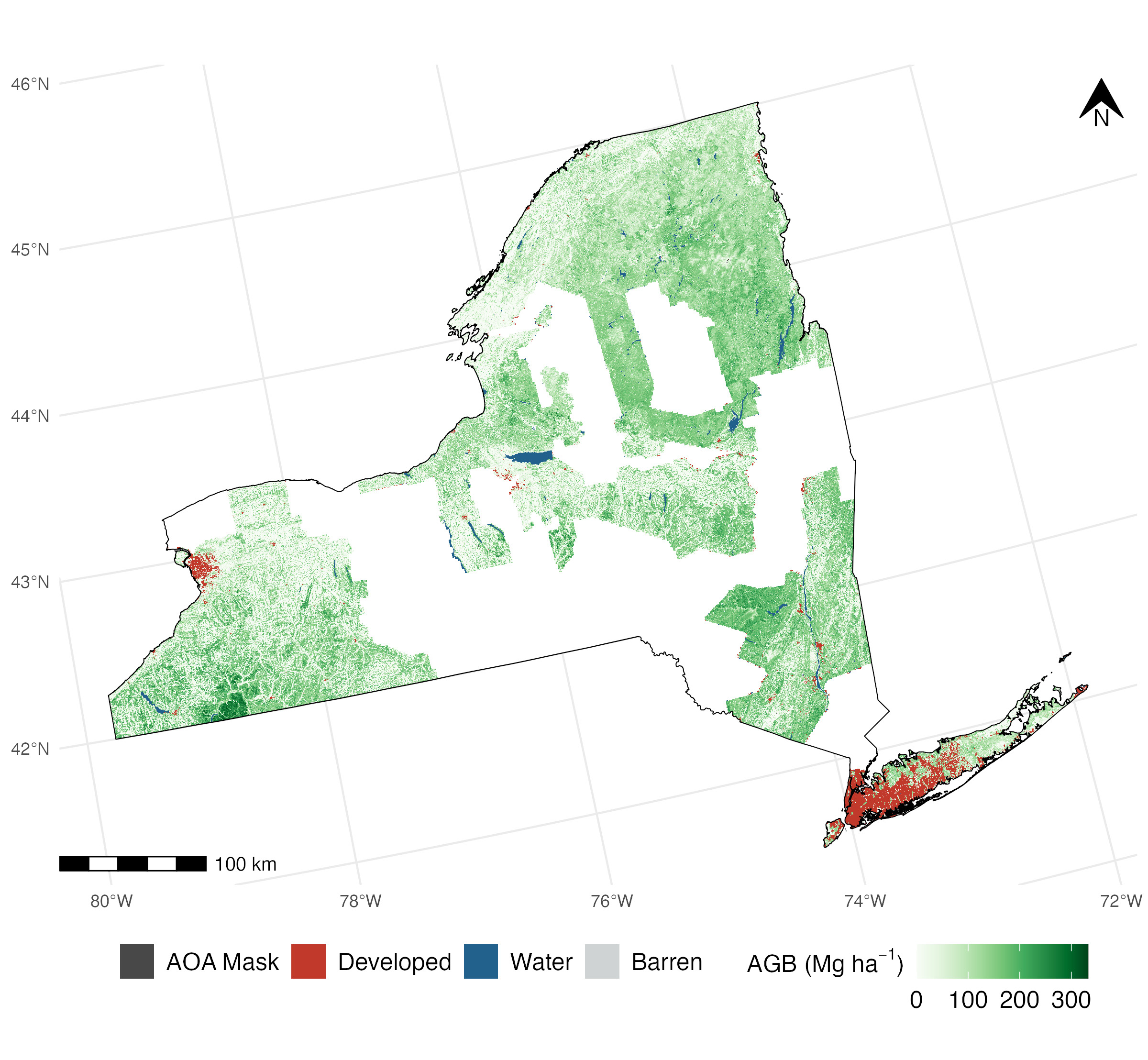
Forest aboveground biomass for New York State, from Johnson et al 2022. In order to make sure users can trust the maps like this we produce, our team spends a lot of time working on validating the accuracy of our maps and figuring out where the model can’t easily predict.
ESIP Machine Learning Cluster
The purpose of this cluster is to educate ourselves and the ESIP community about machine learning through asking and answering questions and sharing experiences and resources. Join the monthly call every third Friday of the month at noon EDT.
Learn more: esipfed.org/collaborate
Location, location, location
We also attempt to talk about how well our model performs across the entire region we're mapping. A lot of spatial data science is very heavy on the “data science” and a bit lighter on the “spatial,” and only presents test-set accuracy metrics without any investigation into what that accuracy actually looks like on a map.
In particular, checks for issues like the spatial autocorrelation among residuals, indicating “hot spots” where model errors are noticeably higher than expected, are often conspicuously missing. We investigate the spatial structure of our predictions in order to identify any such “hot spots” where errors are notably higher than we'd expect. In doing so, we might realize we're missing important predictors that can help improve our model; failing that, we can at least provide information on where our model works best to anyone using our maps.
On top of that, we try to only map places that we think are well-represented in our actual training data, to avoid making predictions in areas that we don't have enough information to model. Machine learning methods are mostly incapable of extrapolation, only “learning” features and generating predictions within the values they were trained on (and often predicting only a sliver of that range). As a result, presenting a machine learning model with new data that's nothing like anything it has seen before will only give you junk predictions.
My current favorite approach for dealing with this is to define the “area of applicability” of a model, which clearly delineates areas which are well-represented in the training set and where our model can safely map. Our hope is that by admitting that our model can't be blindly applied everywhere, we build trust in our users that it can be applied to the areas we think fall within that “area of applicability.”
Trust in the process
None of these steps are perfect, and none are magic for making others trust the model as much as the person who built it. But our hope is that by being thorough and open with the successes and failings of our models, we can build trust in our models and in applied machine learning in general.
This is something we’ve been working on as part of ESIP’s Machine Learning cluster’s “Practical AI” project. We are setting out best practices for how to both build and validate AI and machine learning systems in applied earth science contexts. If you’re interested in being part of this work, join the monthly gathering through the ESIP Community Calendar.