Innovation to Impact. See you at the July ESIP Meeting.
MUDROD – Connecting Semantics, Data Discovery, and Analytics
Hello World!
Today, I’m going to talk about the MUDROD project, which I believe has connected at least three ESIP clusters, including Semantics, Data Discovery, and Analytics.
As this is my first blog, I would like to start with a brief introduction to myself. I am a research assistant at the Spatiotemporal Innovation Center, George Mason University (GMU). My research primarily focuses on building an intelligent geospatial data discovery engine to strengthen the ties between Earth observations and user communities. More broadly, I’m interested in applying machine learning and natural language processing techniques to solving knowledge discovery problems in Earth Science by considering the domain-specific concerns.
Figure 1. Main page of MUDROD
In the past two years, I have been working on the MUDROD project. MUDROD is the shorthand for Mining and Utilizing Dataset Relevancy from Oceanographic Datasets to Improve Data Discovery and Access, which is a collaboration between GMU and JPL, NASA. As you can see from its title, the ultimate goal of MUDROD is to improve data discovery by mining metadata document and user behavior. So why there is a need for better Earth Sciences data discovery? What technologies does it involve? And how does it work? In this short blog, I will only give you general idea without too much technical stuff being involved.
What are the problems in Earth data discovery?
1.Only keyword-matching, no semantic context
If a user searches for “sea surface temperature,” it is understood by traditional search engine as “sea AND surface AND temperature,” but the real intent of this user might be “sea surface temperature” OR “sst” OR “ghrsst” OR …
2.Single-dimension based ranking
There are typically hundreds or even thousands of search hits when you search by a keyword. Many be websites provides some sorts of metrics (e.g., spatial resolution, processing level) to help sort the search hits. It can be helpful sometimes, but it also induces users to just focus on one single data characteristic. What if a user is looking for a data that has both high spatial resolution and processing level?
3.Lack of data-to-data relevancy
In theory, there exist hidden relationships among the data hosted within a data center or across different data centers. In reality, we can only view a particular data after clicking on it without knowing its related data.
How does MUDROD address them?
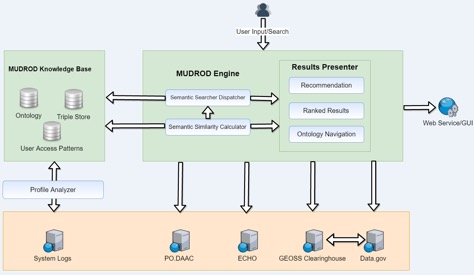
Figure 2. System architecture
1.Query expansion and suggestion (semantics)
Rather than manually create a domain ontology, MUDROD discovers the latent semantic relationship through analyzing the web logs and metadata documents. The process could be thought of as a type statistical analysis. The hypothesis for user behavior analysis is that similar queries result in similar clicking behaviors. The intuition is that if two queries are similar, the clicked data will be similar in the context of large-scale user behaviors. The analysis results would be the similarities between any pair of data. For example, we found that the similarity between “ocean temperature” and “sea surface temperature” is nearly one, meaning exactly the same. These similarities would be very helpful in terms of better understanding users’ search intent. For example, an original query “ocean temperature” can be expanded to “ocean temperature (1.0) OR sea surface temperature (1.0)”. This converted query has been proven to be able to improve both the search recall and precision.
2.Learning to ranking (machine learning)
After discussing with domain experts, we identified about eleven features that can reflect users’ search interests. These features primarily come from three aspects, including user behavior, query-metadata overlap, metadata attributes. From there, we trained a machine learning ranking algorithm with human-labelled query results. The reason we use machine learning here is that it is difficult to weight these features, especially the number of them can be larger down the road. After that, we use the machine learned model to predict the results of other unseen queries.
3.Recommendation (machine learning)
To find the relatedness of different data, two types of information are considered, user behavior and metadata attributes. In terms of the metadata attributes, it is straightforward that we just need to compare the text of the metadata documents. For the user behavior based recommendation, we just need to find the most similar user(s) to you, and then find the data that have been clicked by your most similar user(s) but you haven’t. We can get the best recommendation for us by merging the results from these two methods.
Next steps
We are working on a real-time log ingestion module. The goal is to ingest, process the web logs and update the back-end knowledge base in a real-time manner. We are actually making some good progress here and probably I will post it in my next blog.
Acknowledgement
- NASA AIST Program (NNX15AM85G) & Mike Little
- SWEET Ontology Team (Initially funded by ESTO)
- All team members at JPL and GMU
More resources:
- Source code: https://github.com/mudrod/mudrod
- Demo: http://199.26.254.151:8080/mudrod-service/